(8 封私信 / 19 条消息) 大模型微调实践必看——一文看懂Deepspeed:用ZeRO训练大模型原理解析及参数含义解释 - 知乎
【里面的视频非常生动,逐帧理解就能搞懂ZeRO的原理、temporary buffer、activation的实在含义】
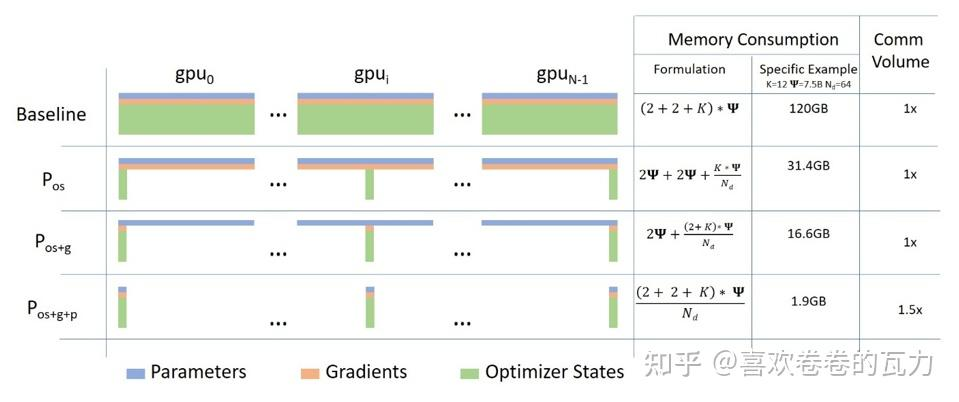
假如GPU卡数为N=64,Ψ是模型参数,假设Ψ=7.5B,假设使用Adam优化器,K是优化器的超参,在64个GPU下K=12,则:
- 如果不用ZeRO,需要占用120GB的显存,A100最大才80GB,塞不下
- 如果用ZeRO Stage1,则占用31.4GB,A100 40GB或者80GB卡都能跑,单机多卡或多机多卡训练的通信量不变【因为没有额外通信,不需要搬来搬去】
- 如果用ZeRO Stage2,则占用16.6GB,大部分卡都能跑了,比如V100 32GB,3090 24GB,通信量同样不变【因为没有额外通信,不需要搬来搬去】
- 如果用ZeRO Stage3,则占用1.9GB,啥卡都能跑了,但是通信量会变为1.5倍
备注:
- 优化器状态 一般包含FP32 Gradient、FP32 Variance、FP32 Momentum、FP32 Parameters
- 梯度和模型参数 一般会用FP16就够了,所以占用大头一般是优化器相关的
用自己的话说,就是ZeRO想做的就是在数据并行的同时,实现模型并行(每块GPU只装$1/N_{GPU}$个模型),同时还要模型的每一部分参数都要在完整的数据集上计算梯度与更新参数(这就是分布式训练中的梯度聚合(Gradient Reduction),注意区分:Gradient Checkpoint(重算),Gradient Accumulation)
核心原理
我自己的通俗理解
- 假设某一块GPU为A,首先我们需要知道,模型的更新需要参数和梯度(from the whole dataset)
- 由于模型并行,A上只存了他那部分的参数(fp16,denoted as $M_A$)
- A上还需要来自全部样本的gradient
- 由于数据并行,A自己管一部分数据$D_A$,当这部分数据反向传播到A上的时候,他计算$M_A$在自己那部分的数据的梯度很容易,很正常
- 在其他地方同样需要计算$M_A$在$D_x$ 上的梯度,这就需要提前把$M_A$复制到(通信代价)到$GPU_X$上(此处需要一个temporary buffer),在$D_x$计算$M_A$的梯度,算完之后再把这个梯度复制到A上,X自己那里的$M_A$及其梯度随后删除【注意:实际上,所有的 $GPU$ 其实是在同一时间处理不同的数据块。对于参数 $M_A$,每块 GPU 都会在自己的显存里算出针对自己那部分数据的“局部梯度”。】
- 这样A那就有$M_A$在整个数据集上的全部梯度(fp16)了,再进行Reduce
- 所有机器在反向传播$M_A$对应层的激活值(activations)可以全部删除了(其他GPU只是不存A的参数,但临时搬来了A的参数,并在反向传播的过程中产生了激活值,因为要求梯度)
- 在反向传播全部计算完成时,就可以在A里面对$M_A$进行更新了
- optimizer里面装了momentums(fp32) variances(fp32) parameters(fp32),其中前面两个是由gradient计算出来的
- 将计算出的新的paramerters(fp32)转换成fp16去替换$M_A$的值
- 进入一下fwd,如此循环
修正后的逻辑小结(以 GPU A 为例):
- 前向传播: 所有 GPU 广播(Broadcast)拉取 $GPU_A$ 的参数 $M_A$,计算并存下激活值,算完后非 A 卡删除 $M_A$ 副本。
- 反向传播: 所有 GPU 再次拉取 $M_A$,结合存下的激活值,各自算出 $M_A$ 在自己数据上的局部梯度。
- 梯度聚合: 通过通信(Reduce-Scatter),所有局部梯度汇聚到 $GPU_A$,求和/平均得到全局梯度。此时所有 GPU 删除 $M_A$ 副本及相关激活值。
- 参数更新: $GPU_A$ 独自使用 FP32 优化器状态和全局梯度,更新 $M_A$ 的 FP32 主权重,并同步回 FP16 的 $M_A$。
- 循环: 下一轮迭代开始。
关于激活值与重算
即便你开启了重算(Activation Checkpointing / Gradient Checkpointing),在计算梯度的那一瞬间,激活值(Activations)必须存在。
为什么?因为**链式法则(Chain Rule)**规定了:没有前一层的输入(即激活值),就无法算出当前层权重的梯度。
让我们拆解来看:
1. 数学层面:为什么必须要有激活值?
假设我们有一个简单的线性层:$y = W \cdot x$
- $x$:输入(也就是上一层的激活值)
- $W$:权重
- $y$:输出 在反向传播时,我们需要计算 Loss 对权重 $W$ 的导数(梯度)。根据链式法则: $\frac{\partial L}{\partial W} = \frac{\partial L}{\partial y} \cdot \frac{\partial y}{\partial W}$ 其中,$\frac{\partial L}{\partial y}$ 是从后面传回来的误差信号(Gradient from next layer),而关键在于第二项: $\frac{\partial y}{\partial W} = x$ 看!梯度的计算公式里直接包含了 $x$(激活值)。 结论: 无论你用什么优化技巧,在计算 $W$ 的梯度那一刻,显存里必须有 $x$。如果你之前没存(或者删了),那你就必须现场把它重新算出来。
2. 场景对比:普通训练 vs. 重算 (Checkpointing)
既然数学上必须要有 $x$,那“存”与“重算”的区别就在于什么时候拥有它。
A. 普通模式(不开启重算)—— “用空间换时间”
- Forward: 算出 $x$,算出 $y$。把 $x$ 锁在显存里不许动。
- Waiting: 在漫长的等待反向传播期间,$x$ 一直占着显存(这就是显存爆炸的主因)。
- Backward: 轮到这一层了,直接从显存取出的 $x$,乘以传回来的误差,算出梯度。
- Delete: 此时才释放 $x$。
B. 开启重算(Activation Checkpointing)—— “用时间换空间”
- Forward: 算出 $x$,算出 $y$。记下 $x$ 的输入来源(Checkpoint),然后立刻把 $x$ 删掉(或者只留极少量的关键节点)! 省下了巨大显存。
- Waiting: 显存空空如也,很开心。
- Backward: 轮到这一层计算梯度了。
- 重算时刻: 系统发现 $x$ 不见了,于是利用之前记下的 Checkpoint,重新跑一遍 Forward,再次生成 $x$。
- 计算梯度: 拿着刚“热乎”算出来的 $x$,算出梯度。
- Delete: 再次删除 $x$。
3. 在 ZeRO (分布式) 环境下的特殊影响
这才是最关键的。在 ZeRO-3(参数切分)的场景下,开启重算会带来额外的通信开销。 回顾你的 $M_A$ 例子:
- 如果不重算:
- Fwd: 拉取 $M_A$ -> 算 $x$ -> 存 $x$ -> 删 $M_A$。
- Bwd: ($x$ 已就位) -> 拉取 $M_A$ -> 算梯度 -> 删 $M_A$。
- 通信次数: 2次拉取 $M_A$。
- 如果开启重算:
- Fwd: 拉取 $M_A$ -> 算 $x$ -> 删 $x$ -> 删 $M_A$。
- Bwd:
- 发现缺 $x$,需要重算 Fwd。
- 重算 Fwd: 再次拉取 $M_A$ -> 算出 $x$ -> 删 $M_A$。
- 真正 Bwd: 再次拉取 $M_A$ (因为要算关于 $M_A$ 的梯度) -> 结合 $x$ 算梯度 -> 删 $M_A$。
- 通信次数: 3次拉取 $M_A$! (初始 Fwd 1次 + 重算 Fwd 1次 + Bwd 1次)。 总结:
你开启重算后,确实不需要“长期存储”激活值了,但在反向传播计算梯度的那个微小时间窗口内,激活值必须被临时复现出来。
对于 ZeRO 来说,这意味着为了复现激活值,它可能需要多进行一次参数通信,这是用通信带宽 + 计算时间去换取显存空间的极致做法。