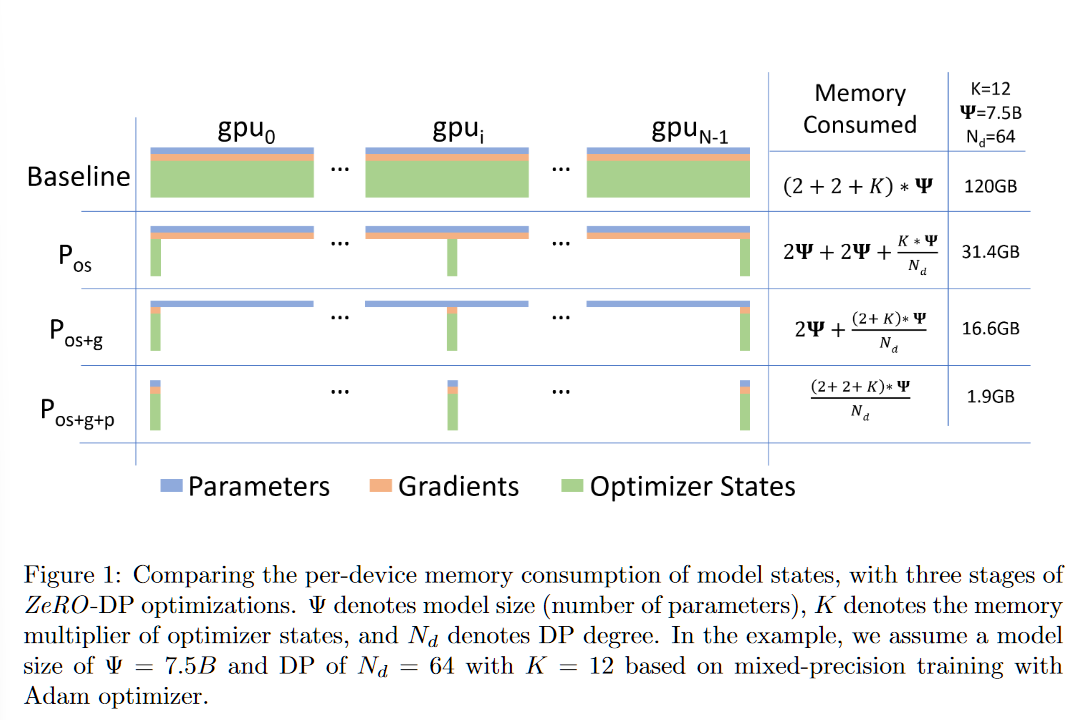
在混合精度训练(通常是现今大模型训练的标配)中,显存的占用主要由**模型状态(Model States)**决定。
1. 为什么 Baseline 的公式里都要乘以 2?
这其实是指数据占用的字节数(Bytes)。
在混合精度训练中,为了加快计算速度,前向传播(Forward)和反向传播(Backward)通常使用 FP16(半精度浮点数) 进行计算。
-
FP16 每个参数占用 2 字节(16 bits = 2 Bytes)。
-
因此,图中公式里的第一个
2是参数(Parameters),第二个2是梯度(Gradients),它们都是以 FP16 格式存储的。 -
公式写成
(2 + 2 + K) * Ψ,括号里的2 + 2就代表了模型在计算过程中必须实时持有的 FP16 参数和 FP16 梯度。
2. 为什么 参数:梯度:优化器状态 = 2 : 2 : K ?
这里有一个重要的概念:主权重(Master Weights)。
虽然计算用 FP16,但为了保证更新时的精度不丢失,Adam 优化器在后台必须维护一份 FP32(全精度,4 字节) 的参数副本。
我们来拆解一下这三者的比例:
-
Parameters (2 字节): 用于前向/后向计算的 FP16 权重。
-
Gradients (2 字节): 算出来的 FP16 梯度。
-
Optimizer States (K 字节): 这是大头。以 Adam 为例,它包含:
-
FP32 权重副本 (4 字节): 更新完后会转回 FP16 给下一轮用。
-
Momentum 动量 (4 字节): Adam 的一阶动量。
-
Variance 方差 (4 字节): Adam 的二阶动量。
-
3. Adam 的 K=12 是怎么算出来的?
基于上面的拆解,K 代表的是优化器状态(Optimizer States)总共占用的字节数。
对于 Adam 优化器:
-
FP32 Master Weights: 4 字节
-
FP32 Momentum: 4 字节
-
FP32 Variance: 4 字节
-
总计: $4 + 4 + 4 = 12$ 字节。
所以公式里的 $K = 12$。
总结一下 Baseline 的 120GB 是怎么算的:
在这个例子中,模型大小 $\Psi = 7.5B$(75亿参数):
-
FP16 参数: $7.5 \times 2 = 15 \text{ GB}$
-
FP16 梯度: $7.5 \times 2 = 15 \text{ GB}$
-
Optimizer States: $7.5 \times 12 = 90 \text{ GB}$
-
总计: $15 + 15 + 90 = 120 \text{ GB}$。
延伸思考:
-
如果不用 Adam 用 SGD 呢? SGD 只有动量(或没有),K 就会变成 8 或 4。
-
如果不开启混合精度(纯 FP32)呢? 参数和梯度会变 4 字节,但不需要 FP16 副本,比例会发生变化。但目前主流框架(如 DeepSpeed/Megatron)默认都是按照这个混合精度的比例来设计优化的。